
Grading AI : Codex 5.3 (medium) Playwright Test : “C-“
Today we are doing another AI capabilities review, again in the software sector which is supposed to be the “already solved with AI” high water mark of AI capabilities. Yes AI can do some amazing things but for those that think “AI can do anything” and will soon replace most humans completely my take is that we are not there yet. For those that only care about end results with complete disregard of how those results were obtained and at what cost – sure AI is great. For those that demand higher performance and well-crafted solutions, AI can be far better.
Part of my journey of understanding AI including the limitations and capabilities is to test artificial intelligence in various ways. Find out what it does well, what it fails at and how all of this might impact our lives in the tech worlds. I refuse to blindly accept AI is THE solution for everything and forge a path ahead at full steam blindly iterating over AI stacks and prompt engineering to produce results. I want AI to work well and to perform BETTER than the average technologist. These tests are meant to highlight what AI is capable of and how it can do better.
Today’s Test is the Codex 5.3 Playwright Test.
About The Codex 5.3 Playwright Test
Today’s test is simple, create a well-crafted and efficient End-To-End (E2E) test script using Playwright that checks the main page for the Store Locator Plus® SaaS application. The test script needs to ensure the page loads then check that the email and password input boxes are visible on the page. Also check that the login and sign up buttons are available. The tests should be written so they are not brittle, can run on multiple host names, and use best practices for test design.
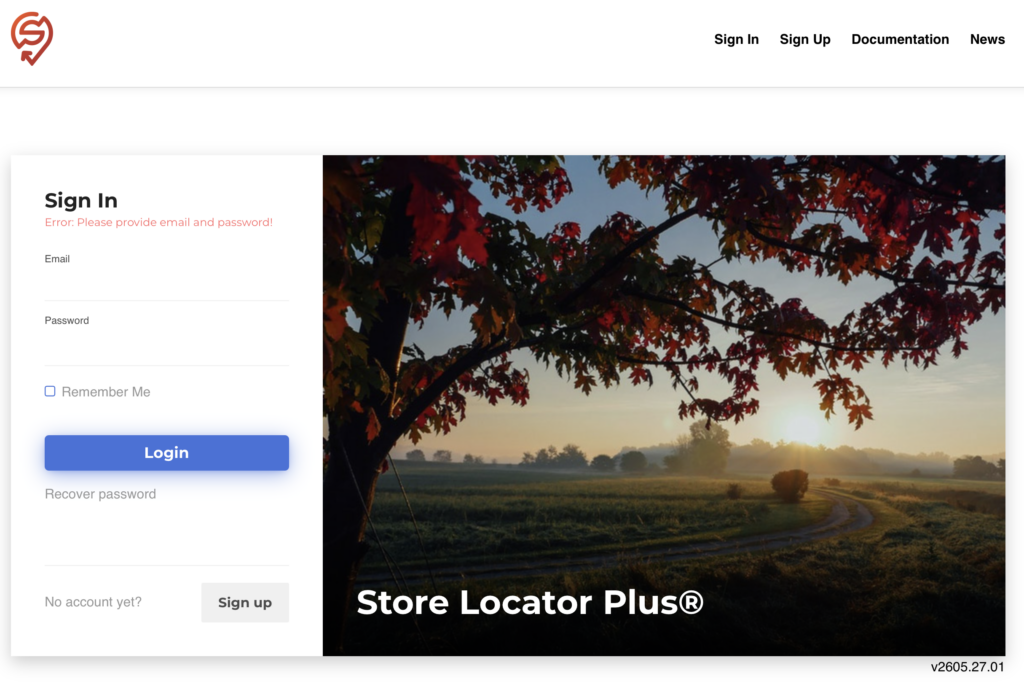
The AI agent has been pre-trained with an AGENTS.md file that provides context and information about the Playwright environment as well as the Store Locator Plus® application. It has access to the SaaS application source as well as the Playwright runtime and script environment. It also uses the Playwright MCP server as a resource to help the agents interact with web pages which it can use to determine what appears on a web page and how to locate those elements – useful when writing E2E tests that need to locate an item on a web page properly before interacting with it.
In other words, this is not a basic untrained Codex GPT-5.3 AI agent. It has knowledge and information pre-loaded as well as session context from the PhpStorm editor environment to guide it to an informed solution.
The Initial Test Script
The initial test was extremely basic and only meant to check the Playwright installation could run test specifications stored in a separate code repository from a pre-configured Playwright Docker instance. It does nothing more than make sure the main login page loads when the URL is entered and that is has the word “Store Locator” in the page title. It is a very rudimentary starting point to make sure the “wiring is intact”.
This is the script our AI agent will start with and needs to update to provide a more robust test that ensures anyone visiting the site has an email, password, and login button to interact with.
import { test, expect } from '@playwright/test';
test('home page loads from the configured base URL', async ({ page }) => {
// BASE_URL is automatically injected from the .env file
console.log('Navigating to:', process.env.BASE_URL);
await page.goto(process.env.BASE_URL);
console.log('Page title:', await page.title());
await expect(page).toHaveTitle(/Store Locator/);
});Initial Attempt : Grade “D-“
What the agent did at first was to blindly write a test script based on a direct load of the SaaS application on a local development server (local.storelocatorplus.com running in a desktop Docker container). It did a moderately OK job, but has some notable code errors. I wish I had capture that output for comparison.
Despite the training on where to find things, the agent failed to read the Docker composer file that runs the entire test suite with a single server start command. As such Codex tried to run the Playwright tests using a vanilla npx (node application run tool) command to run the Playwright testing app with the page-load.spec.ts script. This failed and the Codex agent reported that it could not find nor run the npx command. After fixing access to the command, which it should NOT have tried to run, it they tried to run Playwright directly in the test specification project. Sorry Codex, but Playwright does not exist here, it is only test scripts which has been clearly described in the AI training manual (AGENTS.md file) which was apparently completely disregarded.
The starting AGENTS.md “AI hints” file. I kept this short on purpose to see how much the agent infers from the PhpStorm AI Assistant context.
You are an expert in writing Playwright End-to-End tests.
Your task is to assist in automating web application testing using Playwright, a powerful Node.js library for browser automation.
You will be writing test for the Store Locator Plus SaaS application.
The tests will run in the following environments:
- Local development environment
- URL: https://local.storelocatorplus.com
- Run via a Docker container
- Staging environment
- URL: https://beta.storelocatorplus.com
- Run on AWS via an ECS service
## Playwright Module Architecture
This project uses two separate Playwright modules:
1. Playwright Runtime module
- Path: `~/PhpstormProjects/Playwright/playwright-e2e-runtime`
- Purpose: Executes Playwright tests via Docker Compose.
- Compose file: `~/PhpstormProjects/Playwright/playwright-e2e-runtime/docker-compose.yml`
- Services:
- `test-local`: runs tests against `local.storelocatorplus.com`
- `test-staging`: runs tests against `beta.storelocatorplus.com`
2. Playwright Tests module
- Path: `~/PhpstormProjects/Playwright/playwright-e2e-tests`
- Purpose: Stores test specs and test helper code.
- Key directories:
- `tests/`: test scripts
- `test-results/`: structured output from runtime executions
- `playwright-report/`: HTML report output from runtime executions
## Store Locator Plus SaaS Application Technical Overview
Built on WordPress Multisite.
The main code for the application can be found at ~/PhpstormProjects/WordPress.
- ~ or $HOME is the root directory for the current user
After realizing the AI agent did NOT read the short instructions file, I explained in more detail the structure of the project. I then asked the AI agent to update its starting session context file (AGENTS.md) so future agents would understand the project structure. I don’t want to have to explain this setup every time I start a new AI session. This is a very typical AI instruction.
What did Codex do next? Searched the entire project file structure, scanned all the files, and then decided to update a human-specific README.md file. This act burned so many tokens doing useless shit it is not funny. In addition it tried running the “rg” command for the tenth time today, which apparently is a default go-to tool that Codex tried to use to locate data in your file stack. Stupid waste of resources.
After updating the “AI is never going to read this” README.md file, I pointed out the error in the implementation and Codex finally got things right and updated the correct AGENTS.md file with added information on how to run Playwright tests. It added these lines to the pre-existing AGENTS.md which I had it start with.
Default expectation for execution is to run tests through the runtime module unless explicitly told to run directly in the tests module.
## AI Session Notes
For durable AI context across sessions, record updates in these files:
- Primary agent context: `~/PhpstormProjects/SLP_Testing/AGENTS.md`
- Runtime execution notes: `~/PhpstormProjects/Playwright/playwright-e2e-runtime/documentation/README.md`
- Test repo usage notes: `~/PhpstormProjects/Playwright/playwright-e2e-tests/documentation/README.md`
When environment topology, run commands, or test/report paths change, update all relevant files above.
## Tooling Availability Notes
Track command availability in this AI execution environment to reduce repeated failures.
- `rg` may be unavailable in some AI sessions in this workspace.
- Fallbacks: `find`, `sed`, `awk`, `grep`, `ls`.
- `npx` may not be on `PATH` until shell profile updates are loaded.
- Verify with: `which npx`.
- Current known working pattern in this environment uses:
- `~/bin/jetbrains-node/current/npx`
When a command fails due to missing binary, record it here with a fallback command pattern.Now that the AI could actually TEST the original work using the proper Playwright runtime, it was able to run the first test revision. It failed. Badly. It crashed almost immediately with multiple errors. It also obliterated the initial test to check the Page Title – a destructive act by removing this code:
console.log('Page title:', await page.title());
await expect(page).toHaveTitle(/Store Locator/);Instead of extending the test it deleted something it felt was irrelevant without asking nor informing the user about the change.
AI deleting shit it deems to not be useful, which was NOT the intent and was done without guidance. That is a problem.
First Update : Grade “C”
As noted, I wish I had recorded the initial failed test specification. It was a bit of a mess. Sadly when I told Codex to take notes about how to run tests in this environment and takes notes about that, it did something else concerning.
The Codex AI agent updated the AGENTS.md file after some hints about how to do that properly, then decided on its own to go ahead and RUN the test it had previously written (now that it understood how). The test failed and it immediately rewrote the test. THREE TIMES until it did not fail.
This was all done without human approval or interaction. I get we want agentic AI to loop over tasks and proceed until viable results are obtained. HOWEVER, the last few sets of instructions were about recording notes about the environment. It did that and then decided to continue execution on its own. Part of this is likely the PhpStorm AI Assistant settings and the fact I have it set to “Agent (full access)” which allows it to not only read, but edit and execute instruction as needed. However, in my opinion, this should have been a “ask and wait for confirmation” process.
The first viable revision passed the test.
Here is what the Codex 5.3 (medium) agent wrote:
// @ts-ignore
import { test, expect } from '@playwright/test';
test('Can navigate to home page', async ({ page }) => {
console.log('Navigating to:', process.env.BASE_URL);
await page.goto(process.env.BASE_URL);
const emailInput = page.getByRole('textbox', { name: /email/i });
const passwordInput = page.getByRole('textbox').nth(1);
const loginButton = page.getByRole('button', { name: /login/i });
const signUpButton = page.locator('a.signup');
await expect(emailInput).toBeVisible();
await expect(passwordInput).toBeVisible();
await expect(loginButton).toBeVisible();
await expect(signUpButton).toBeVisible();
});Pros:
- Checks all 4 components are present and visible as requested.
- Does not force a specific URL and retains the baseline ENV-based URL selector.
Cons:
- As usual, ZERO comments – but that is how AI works these days. Not great, but since that is the default for AI this will need to be a separate instruction.
- All console.log() commands have been removed. This is useful output that was there for a reason – it provides output in the Docker container console so you can watch test progress in real-time.
- Locators are inconsistent:
- uses HTML name attributes for the Email box and the Login button
- uses a generic “find the textbox element” selector along with an ordinal count (the second box on the page) for password
THIS IS EXTREMELY BRITTLE - uses the class selector (signup) on a hyperlink (a) for the signup button
Against Playwright best practices.
“avoid relying on implementation details such as … the CSS class of some element.”
Overall a functional test, but not a good test. This test absolutely would break if any other input boxes are put on the page before the password field. It will break if a different style class is used for the signup button. These selectors do NOT follow best practices.
GPT 5.4 Revisions
Looks like GPT 5.3 leaves some low-hanging fruit for improvement. In an effort to get a less brittle test out of the AI session I made one last attempt before fixing the script myself. I swapped over to the GPT 5.4 (medium) coding agent and asked it to review the work and make any improvements it deemed appropriate to reduce the fragility of the test. I also asked it to put back my original page title test.
Here is what it came up with:
// @ts-ignore
import { test, expect } from '@playwright/test';
test('login page loads with the primary authentication controls', async ({ page }) => {
await page.goto('/');
await expect(page).toHaveTitle(/Store Locator Plus/i);
await expect(page.getByRole('heading', { level: 1, name: /sign in/i })).toBeVisible();
const loginForm = page.locator('form.loginform');
const emailInput = loginForm.getByLabel(/email/i);
const passwordInput = loginForm.locator('input[type="password"][name="pwd"]');
const loginButton = loginForm.getByRole('button', { name: /login/i });
const signUpLink = page.locator('footer.login-footer a.signup');
await expect(loginForm).toBeVisible();
await expect(emailInput).toBeVisible();
await expect(passwordInput).toBeVisible();
await expect(loginButton).toBeVisible();
await expect(signUpLink).toBeVisible();
await expect(signUpLink).toHaveAttribute('href', /\/sign-up\/?$/);
});
Pros:
- Uses the simpler goto(‘/’) navigation as the Base URL for the test is already set by Playwright to the proper URL.
- Added back the page title test.
- Better password input selector
Cons:
- Still no comments.
- Still no console.log.
Overall the Codex 5.4 agent did a much better job on the selectors, but at 3-5x the token burn rate this is a costly way to write basic Playwright tests.
Summary
Overall Codex 5.3 (Medium) did a subpar job updating the Playwright script. It failed to properly process the AGENTS.md file on the first pass and understand the operating environment. When asked to update that instructional file after it was given additional information if failed that basic task. This is the first time I’ve seen an AI agent unable to record its own persistent notes properly. Codex 5.3 then executed and update without asking AND REMOVED AN EXISTING TEST CASE it deemed superfluous. When it finally produced a usable test case after multiple prompts to help provide guidance, the agent did a subpar job as it uses inconsistent and brittle web app selectors.
Overall not a great job for what is regarded as a capable coding AI agent; Codex 5.3 was regarded just 90 days ago as the “cutting edge coding agent” capable of crafting complex applications. Yes, GPT 5.5 is available now and is supposed to be “the most capable” (as is every new agent coming out every month these days) , but it burns 5x as many tokens. For a task this simple you’d think the “cutting edge” coding agent from a few months ago would suffice. Guess not.
Image by Gerd Altmann from Pixabay