
AWS LEMP Stacks and EFS Issues
Lesson learned — if you are using EFS on production systems you want to be using provisioned throughput mode.
But, before we get into that, let’s go over the details of this implementation…
Service Configuration
We utilize AWS EC2 instances to run multiple WordPress sites hosted in different directories. The configuration is fairly standard: 2+ servers configured as part of an load-balanced cluster. The servers run from the same image meaning they use the same underlying software stack.
Part of that image includes a mounted EFS (Elastic File Storage) directory , used to share WordPress resources between all nodes in the cluster. The original architecture was designed to host not only the typically-shared wp-content/uploads folder of WordPress via this EFS mount but also the code. The thought was that sharing the code in this way would allow a system admin to easily update WordPress core, plugins, or themes from the typical wp-admin web login. Any code updates would immediately be reflected across all nodes.
EFS Web App Code Hosting – A Bad Idea
Turns out this is a bad idea for a few reasons. First of all, EFS volumes are mounted using the NFS4 (network file storage) protocol — this defines how the operating system handles file read/write operations for a network mounted drive. While NFS4 is fairly robust, the throughput of ANY network drive, even on a high speed AWS data center backbone, is much slower than a local drive such as an EBS volume.
That means that even on a good day every PHP file, JavaScript file, or anything else needed to serve up that WordPress web page are going to be a bit slower than normal.
However, the bigger problem comes to light if you happen to choose the default, and pushed as “the mode to use” by Amazon, EFS throughput mode known as “Burst mode”.
An EFS Burts Mode Failure
It turns out that in EFS burst mode the EFS volume is allowed, by AWS-created internal rules, to only manage a limited amount of file I/O. The formula is a bit odd where it looks at how much of the disk you are using and decides that is your limit. In our case a 6GB stored volume meant a cap of I/O requests at 300Kibps.
However, on a busy server you can easily surpass this limit. Burst mode, as the name implies, lets you temporarily exceed this baseline limit. Each time it grants you extra I/O to keep up with disk requests, say an extra 300Kibps for the next 60 seconds, it deducts from an arbitrary and mostly-hidden “Burst Mode Credits” for your AWS account. Supposedly you can view your active credits via Cloud Watch or other AWS metric monitors, but none of the links in the AWS documentation work.
Turns out there is a CloudWatch metric, you’ll need to enable that service for your account first, that is on the EFS dashboard that gives you a clue — the Burst Credit Average Value.
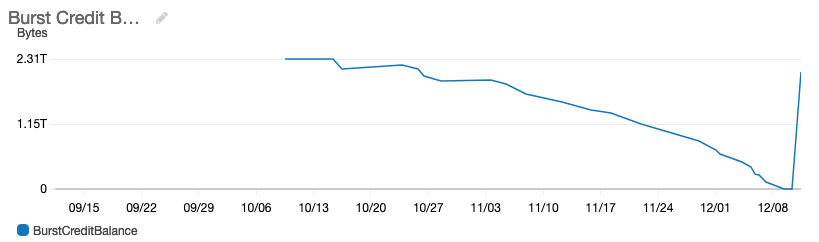
As you can see from the chart, our new EFS volume that was hosting the code and shared content slowly depleted over time. The end of the chart, where it reaches 0 is where all hell broke lose. The spike at the far right — the ramp up in credits on our account after moving to provisioned mode.
Running Out Of Credits
The problem of running out of credits can wreak havoc on your web apps. When you run out of credits, AWS does not notify you. Instead is just throttles your data I/O to something far less than your baseline. In our case the EFS volume was allowing maybe 10Kibps, max, for hours.
What does that low throughput level mean? Reading files takes FOREEVVVVEERRR. A simple display of a text file, an affair that typically takes less than a second, is now taking over a minute.
How does this impact web apps, like WordPress PHP code hosted on the EFS volume? It kills the app. The drive is not sending back the PHP code fast enough. PHP has built-in time limits to wait for that sort of thing. Exceed that limit and PHP dies inexplicably with a random and mostly useless error message. In our case the PHP-FPM accelerator made things works as the only error was a cryptic “upstream connection failed”. No other indication as to what might be wrong.
Ensuring EFS Throughput
Turns out there is an easy way to prevent this throttling — the AWS “dont’s use this unless you know what you are doing” provisioned throughput mode for EFS volumes. With provisioned mode you purchase a guaranteed amount of throughput. In return you pay an additional fee for that privilege.
In our case setting throughput at 10Mibps , more than 5x our maximum-ever I/O on the EFS volumes, adds just $60/month maximum fees to our EFS service. The fees are calculated on how much throughput you actually use, so in our case the maximum is $60 but it would be surprising to see more than $10-or-so in accrued fees.
Once we turned on our guaranteed-throughput our EFS volume, and related web apps, came back to life.
Improving The Architecture
Moving forward we have started separating the code part of the web apps from the shared resources like the WordPress uploads folder. Uploads are shared between the nodes of the cluster. The code, however, is stored on each server independently.
This improves performance slightly and eliminates possible throughput issues as our web apps continue to ramp up in total traffic and number of clients served. It also means the code is better secured — if it were to be compromised it would only be on one node in the cluster and can be easily fixed by killing the compromised node and starting a new one with the known-good baseline software image.
The only downside to this approach is all code updates now need to be managed on a separate outside-the-cluster software-image server. That means a multi-step process to update plugins or themes. A small price to pay for better performance and improved security.
Have some AWS tips to share?
Built your own WordPress server cluster for high availability and performance? Let us know what your setup looks like in the comments.