
DGX Spark Benchmark Testing
In my news feed this morning was an article about John Carmack and his results benchmarking the DGX Spark. The simplified summary of his X post, the DGX Spark is only pulling about 100 Watts (W) of the 200W rated power consumption. The models are showing far less than the 1 PFLOP throughput NVIDIA claims for the Spark.
I’m not an AI expert. Hell, I barely consider myself AI proficient and I’m not even sure about that. However, I do recall the “asterisk clause” related to the DGX Spark performance; It was something along the lines of “in very specific test conditions” when it comes to the DGX Spark 1 peta FLOP performance metric. It also requires a specific type of model , FP4 if I recall, and often mentions inference processing and optimizing zero value parameters. Some AI geek-speak stuff like that.
For those that don’t know the inner workings of AI “thinking” , my super-simplified view is that the AI brain boils down to a super complex probability engine built entirely on math. How fast it “thinks” – processes requests and returns an answer – can be measures in how fast it does math. In this case we are talking FLOPS, or “floating point operations per second” which is one match calculation per second that involves decimal places. A PFLOP is a peta FLOOP , where peta is 10 to the 15th power. Most people are now familiar with “giga” which is a few zeros more than “mega”. A PETA is a lot more zeros than that, so a PFLOP is a LOT of math happening in one second in a DGX Spark.
| Prefix | Decimal value | Power of 10 | Exact binary value |
|---|---|---|---|
| giga | 1,000,000,000 | 10⁹ | 1,073,741,824 |
| tera | 1,000,000,000,000 | 10¹² | 1,099,511,627,776 |
| peta | 1,000,000,000,000,000 | 10¹⁵ | 1,125,899,906,842,624 |
| exa | 1,000,000,000,000,000,000 | 10¹⁸ | 1,152,921,504,606,846,976 |
I was curious about the claims that John Carmack made on X as well as the follow on by Awni Hannun and what it means for the DGX Spark. I did expect to pay a premium for being an early adopter. I also expect that the small form factor in a desktop-friendly consumer device is not going to perform anywhere near as well as more specialized hardware or hardware with a larger footprint. While we all love small compute devices, in the world of computer hardware and pushing to the edges of compute power, size does matter; Larger units dissipate more heat. Anyone that has worked in computer science for long enough knows that thermal management is the most prevalent issue when it comes to hardware throughput. We’ve been dealing with it since the days of applying “cpu gloop” to the first math coprocessors so the heat sink could keep the chip from burning itself to a crisp.
Let’s see what the DGX Spark can do with some AI-built and online benchmarks.
AI Benchmark Testing AI
I’ve never run an AI benchmark before, and since I’m new to this experience I decided to work with a pre-trained AI agent via a custom GPT built on OpenAI GPT 4o. I am curios about how the existing AI tools, like ChatGPT, can help develop and test artificial intelligence – are the bots good enough now to build better bots? Let’s start with having it help with DGX Spark benchmarks.
First step – open the DGX Spark dashboard and use the built-in Jupyterlab interface to run our tests. I already have NDVIDIA Sync setup and connected to the Spark, so one click and I’m into the dashboard.
Opening Jupyterlab in a browser reveals the full interface.
Chat wants me to open a new notebook – easily located under the File | New menu – and start a new python applet.
First test, ensure CUDA and PyTorch are available (they are).
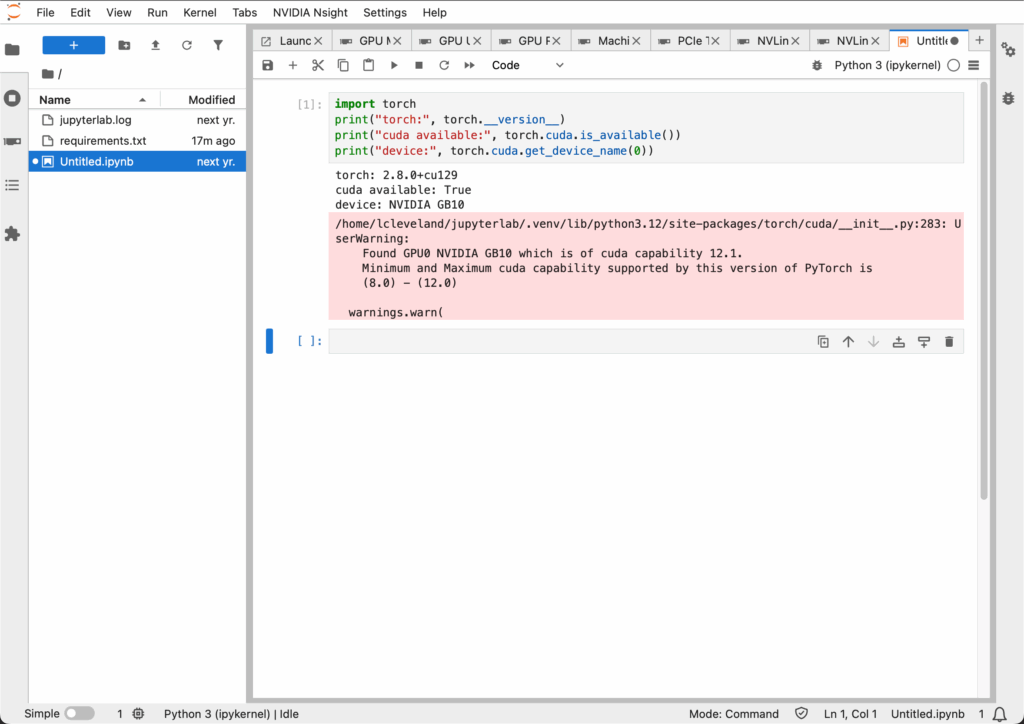
Then load up the AI-written test and monitor the system.
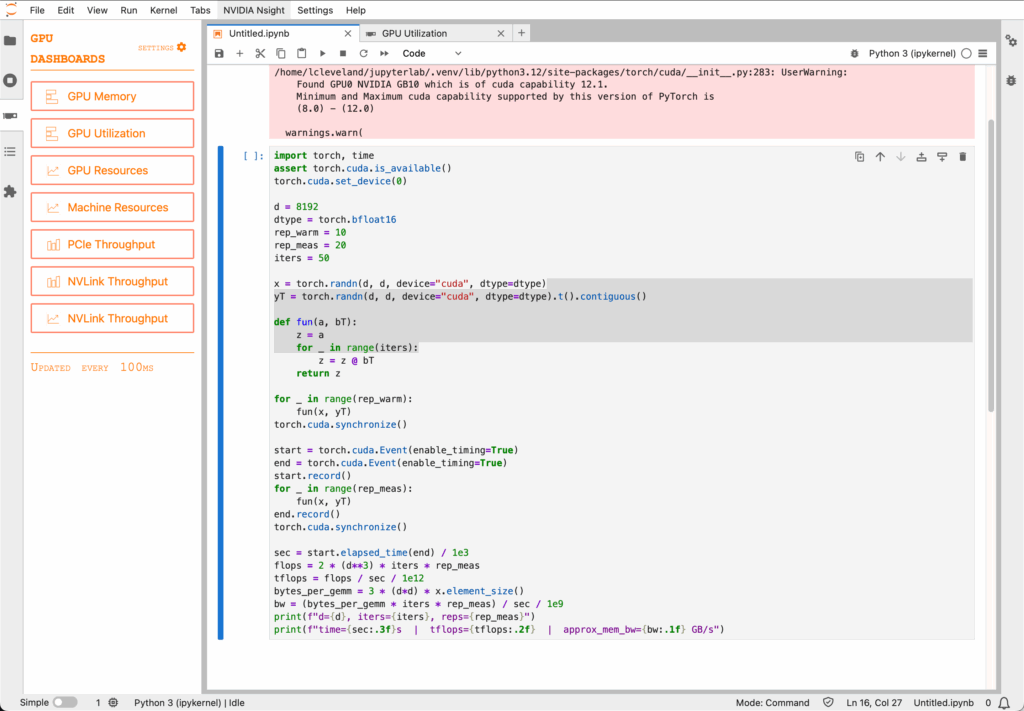
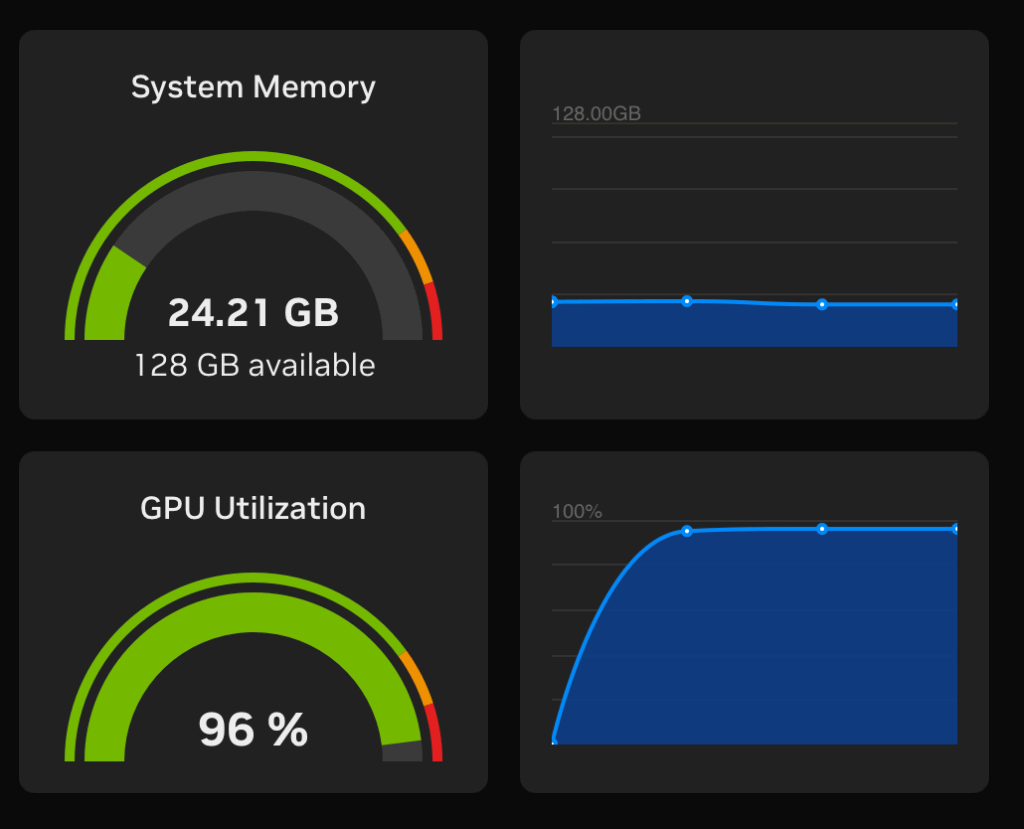
In this test the run was too quick to get a screen shot of the various GPU Dashboards. The main dashboard showed 100% GPU usage for a moment and the GPU0 graph was full out, but was gone before I could grab a screen shot. Here are the results of the ChatGPT enabled test:

In the test ChatGPT wrote, it is using PyTorch and the cuda library to run the test. PyTorch being the machine-learning framework (set of libraries) built on Python to make AI coding easier. CUDA is the NVIDIA specific library for PyTorch to maximize throughput on their GPUs.
Within this setup it created a 2-D Tensor with a square 8192 x 8192 shape using a float16 D-type. For non-math/computer nerds a tensor, in over simplified terms, is a set of numbers in an array. Most people are familiar with a 2-D tensor, in the form of a spreadsheet – rows and columns of numbers. For those than want to nerd out more – a 3-D tensor would add another dimensions to the array (think of it as tabs in a spreadsheet workbook), and more complex models can be created in 4-D … n-D tensors. The float 16 data type is a standard computer data type that is a “decimal number”, in this case a 16-bit floating point number.
Our test processes a memory-array that is made up of 8,192 x 8,192 16-bit floating point numbers.
Our test results show that running this process took just over 13 seconds which equated to 83.41 TFLOPS or .08 FLOPS and had an estimated memory bandwidth of 30.5 GB/second.
This shows us super simple benchmark tests can be run via the Jupyterlab browser interface on the DGX Spark, but it didn’t really push the hardware.
Awni Benchmark Test
Let’s try the benchmark test that Awni posted on X.
import time
import torch
d = 8192
x = torch.randn(size=(d, d)).to(torch.bfloat16).to("cuda")
y = torch.randn(size=(d, d)).to(torch.bfloat16).to("cuda")
def fun(x):
for _ in range(50):
x = x @ y.T
return x
for _ in range(10):
fun(x)
torch.cuda.synchronize()
tic = time.time()
for _ in range(10):
fun(x)
torch.cuda.synchronize()
toc = time.time()
s = (toc - tic)
msec = 1e3 * s
tf = (d**3) * 2 * 50 * 10 / (1024 **4)
print(f"{msec=:.3f}")
tflops = tf / s
print(f"{tflops=:.3f}")This time I barely had enough time to capture the GPU utilization graph, but I was ready…
Shit, it broke…
Less crashing the second time after restarting Jupyterlab on the DGX Spark, but the results are similar to the AI written test:

Not surprising given they are nearly identical tests, but I wanted to be sure to try the original posted test from Awni for the sake of “purity” when reproducing the test.

That is the same .07 PFLOP throughput.
That CUDA 12.1 notice, that is also an area of concern as some users believe the newer libraries are better performing. We’ll see if NVIDIA provides a pre-packaged update for the Spark with the new PyTorch and CUDA support built in.
Diving In To the Disparity
Turns out my AI assistant, ChatGPT, has similar thoughts on why this may be showing such a disparity in performance. Per my earlier notes, the DGX Spark specifically cites “sparse FP4” data sets. These tests are designed with dense BF16 GEMM tests. Chat explains it quite well…
You’re seeing ~70–80 TFLOPs because the test you ran is dense BF16 GEMM, while the headline “~1 PFLOP” number for Spark refers to NVFP4 (4-bit) math with 2:4 structured sparsity on Blackwell-class Tensor Cores under ideal conditions. That’s apples vs. oranges:
Here is the detailed ChatGPT breakdown:
- Precision & sparsity: Peak “1 PF” assumes FP4 + structured sparsity (2:4), which effectively doubles the math throughput vs dense. Dense BF16 runs much lower by design.
- Kernel & layout effects: Your microbenchmark uses a Python loop and an on-the-fly transpose; cuBLAS heuristics, data layout, and problem size (tile fit) can easily leave 30–40% on the table if not tuned. cuBLASLt exists precisely to pick better algorithms/layouts.
- “Marketing peak” vs. “sustained real”: The 1-PF figure is a theoretical peak on specific kernels and precisions; sustained throughput on generic dense GEMMs in PyTorch will be lower—often 50–70% of dense-precision peakis perfectly normal without deeper tuning. (Think roofline: you only hit the “roof” if arithmetic intensity, tiling, and memory traffic are just right.)
My View
So, yeah, some marketing fluff which is expected and these tests that are getting the headlines show more of common problem in the “news” and social media these days — the hype cycle. “OH MY GOD – THE NEWLY RELEASED DGX SPARK IS GARBAGE!” is going to garner a lot more clicks. Especially when it is said by someone people consider to be industry experts. Everyone jumped on the conclusions train fairly quickly.
Yes, NVIDIA should be called out for a bit of extra marketing hype, but it shouldn’t take away from the fact that NVIDIA has released a consumer ready plug-and-play device that novices, such as myself, are able to play with and get their hands dirty with the deeper levels of AI. It is perfect for a DIY self-learner such as myself that wants to go way beyond simple prompt engineering and prompt hacking and start pushing on the AI envelope.
For those out there that feel like AI is finally entering the real world of usability, this is a great time to take a deeper dive into the world of AI. Before now it was an amusing plaything that often yielded more work than results in real-world applications. Only businesses with 7-figure R&D budgets could really leverage AI and put it to use as an efficiency or throughput multiplier. Over the past 6-to-12 months, however, it is easier to see real benefits of AI through the ChatGPT/Claude/Grok LLM lens.
These LLMS show what generic language-based AI models can do when they have a large enough prediction matrix (trained LLM like GPT5). What is really interesting is what these LLMs can do when paired with specialized models. Models that know about your code, your marketing insights, your business processes. Models that are based on more than language combined with an LLM front end to parse requests and explain results.
That is where the DGX Spark comes in, for me at least. What can we do if we combined an augmented AI model with business-specific training? The DGX Spark, regardless of the expected lower throughput than commercial models like ChatGPT, lets me test various scenarios without having to spend $30/hour renting time in the cloud — especially when learning and making mistakes.
Feature Image
AI Generated by Nano Banana
via Galaxy.ai