
DGX Spark : Multiagent Testing
I’ve spent a couple of days playing with the NVIDIA DGX Spark using the Open WebUI and gpt-oss:20b model. It is a fairly good mimic of the ChatGPT experience, though it does process queries a bit slower than I’d like. I also learned how to enable direct web access from within the Spark’s LLM and WebUI interface, turns out the Open WebUI app provides this with a little bit of configuration magic. After playing with the basic setup for a few days I decided it was time to skip to some of the more advanced playbook examples NVIDIA gave us. I decided to try to the Multi-agent chatbot example. I’ll summarize the experience with, I got it working – finally, but it was not as smooth as the first Open WebUI and Ollama setup.
SSH Session Timeouts
The multi-agent docker package is huge. The initial bootstrap they have you download is fairly small, but the packaged shell script that it has you run to pull the full Docker kit is not quite as trivial. On the 770 Mbps connection I am on now (supposed to be 1 Gbps, but this is typical for WoW Internet service where you’re lucky to get HALF the advertised speeds most days) it took a solid 40 minutes to download the first package. The problem with that size download is the SSH connection to the DGX Spark would disconnect on a regular basis. There is no direct terminal I/O so there is no keep alive timer being reset. Thankfully the downloads pick back up where they left off, as often the download process would disconnect when my session disconnected. If I were to reload these models, or in future test cases, I will have to remember to run the scripts as detached background processes; Since this is basically a Debian OS, it should follow the standard Linux & operator at the end of a command line to make that happen. I’ll try that out next go around.
Building The Docker Images
After a couple restarts, the packages were in place. Now it was time to have Docker download the rest of the images for the various models and application software. Much like the initial Docker composer package, these images are large. About 120Gb in total. Sadly the Docker image downloader timed out the first time. Then I restarted it again, but the half-backed Docker composer images were loaded thinking it was complete, but it was not. I could connect to the Docker server and pull up the web applet on port 3000, but it was not working. Turns out not all the images and build scripts loaded completely.
This is where things went off the rails.
I had to terminate all running Docker sessions and restart the composer. It got halfway through the builds then dropped the connection, again.
However, this time the DGX Spark was offline completely. The NVIDIA Sync app could no longer find or connect to the Spark.
Reconnecting To The DGX Spark
After a few attempts to connect via a direct SSH session, the sync app is nothing more than a basic wrapper for standard MacOS (Linux) SSH commands, it was clear the WiFi network connection on the Spark was down. I dug out some old Ethernet cables and hard-wired the Spark to my router. I was able to connect to the Spark with the new IP address using the original username and password I configured on the first day.
I rebooted the DGX Spark, but it still was not appearing not the WiFi network. Maybe the Spark disables the WiFi adapter if you hardwire a network connection, but that would be extremely unusual for a Linux distribution. I’ll investigate that issue later.
Once thing I did learn by doing a direct SSH connection to login to the hardwired Spark — the NVIDIA Sync app requires its own key to be added to the knownhosts SSH file. After I had connected via a “self directed” SSH session, I tried using the Add Device option of NVIDIA Sync. It would not allow the new IP address for my DGX Spark to be added as a new device. I constantly received a “key mismatch in knownhosts” error.
Turns out I had to go into ~/.ssh/knownhosts and remove the entries for the new IP address for the DGX Spark. I could then connect the DGX Spark with the NEW IP address that was assigned. Once that was done I could also connect to the Spark from a standard command line SSH session on MacOS.
That is an odd design, and does not follow best practices, but whatever – I got reconnected and the process restarted.
Third Time Is The Charm
On the third attempt, I was able to connect via an SSH session and get the Docker composer setup running. I verified with Docker ps commands, then reconnected via SSH using the tunnel command as provided in the NVIDIA Multi-agent playbook.
Once this was setup I was able to connect to the new WebUI app at http://localhost:3000
DGX Spark Multiagent : RAG Test
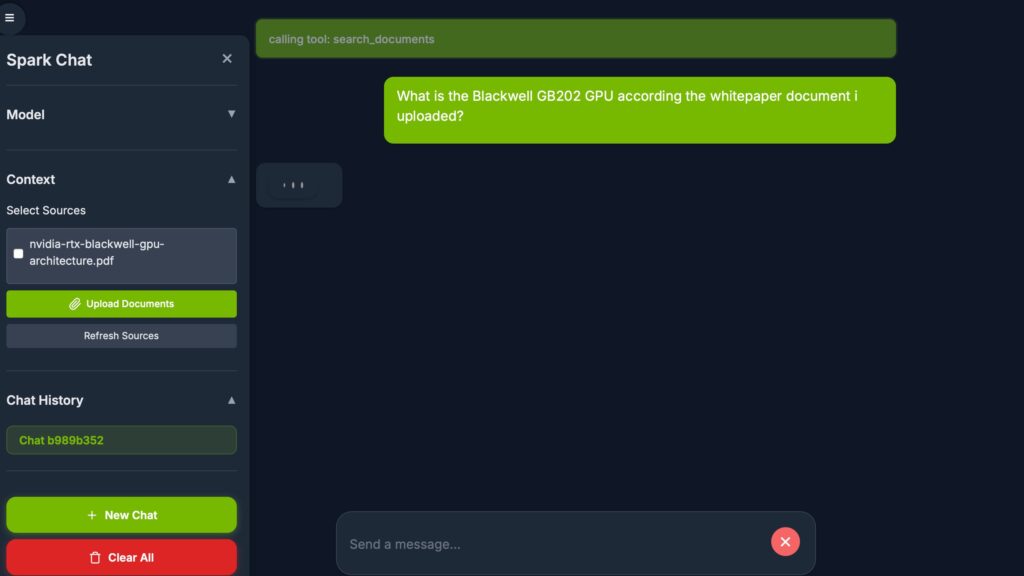
With the new interface and models online, it was time to try a test that was outside the capabilities of the Open WebUI/Ollama gpt-oss:20b system – using a RAG, or “Retrieval Augmented Content”. For this test, NVIDIA has you upload a file that describes the Blackwell chip. The AI interface with RAG enabled will extend its knowledge — the pre-trained neural network that has been built from public online content (typically) — with local content provided by the user (or business). In more realistic scenarios you would do something more along the lines of pointing the RAG interface to an entire document library. Something like the standard operating procedures (SOPs) for your business. When someone queries the AI it will combine its pre-loaded knowledge of “all things on the Internet” with hyper-specialized content from that document set.
For this test , I asked the canned query about the Blackwell chip. Since that document (and the chip) is far more recent than the LLMs training data from a couple of years (or more) back, the only way it can get accurate content is via the RAG — in the case parsing the provided document. Yes, this is a trivial example as in any standard LLM you can upload a document as “local context” and it will parse it as part of the answers it provides. Here we are using a super small data set (the single document) as a stand in for what would typically be a large document set — possibly on a corporate web or file server behind a firewall.
The DGX Spark processed the query fairly quickly. Over the next few days I am interested to see what other ways we can push the AI to provide better answers with these RAG systems. So far, however, the DGX Spark seems to be fairly capable for a tiny little $4,000 box. Not the fastest thing, but certainly has great online support. Despite a few minor kinks, this device seems to be a great resource for expanding AI knowledge in a hands-on environment.

DGX Spark Multiagent : Image Test
One of the modes available on the DGX Multiagent test is an image PROCESSOR agent. Turns out they literally mean PROCESSOR not generator. Rather than go with the pre-loaded prompt, I decided to see what this could do. Given the special occasion today I asked it to draw me a witch eating a birthday cake. The result was amusing, as the AI chat bot decided it would do its best and render then decided to render the image in ASCII art. Turns out it can process provided images, but not render new ones. The standard prompt asking it to get data from an image and process as input worked well.



DGX Spark Multiagent : Code Generation Test
The DGX Spark multi agent has multiple pre-written prompts to test the multi agent system. I used the default prompt to have the AI create a hypothetical AI consultant website. It generated a basic HTML page and matching Style Sheet. It is a rudimentary design showing the code writing powers of AI.
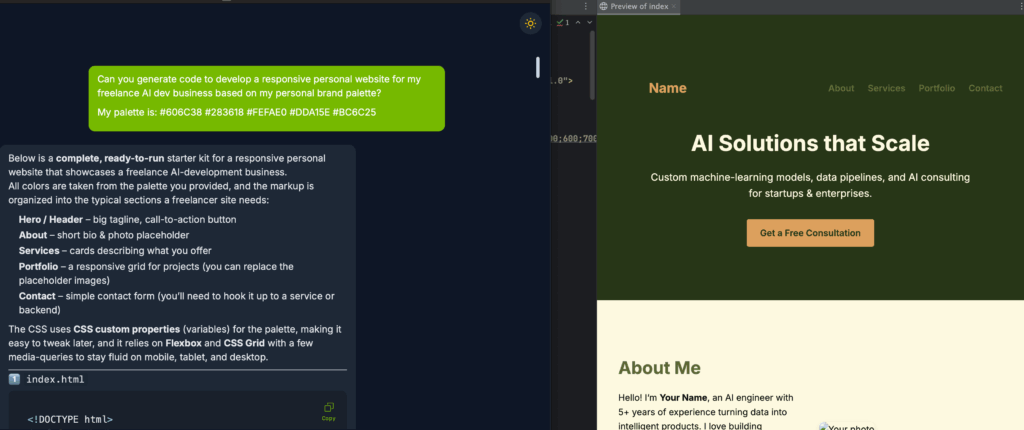
While interesting, the multiagent models are a bit outdated. They also have some built-in limitations that throw errors on the multiagent UX, like this maximum update depth exceeded. It runs “out of the box” but definitely needs tweaking.

The quality of the output shows some of the issues with the earlier models provided here. Poorly formed word choices, capitalization, and such. Things earlier AI from years ago… as in late 2024 (almost a whole 12 months ago) are present here with bad decisions made throughout. This shows how much better the newer neural networks in newer large language models have progressed.
The model is also not able to keep up with follow-on requests. It is fairly obvious after less than an hour of testing that anything taxing the system memory, 120GB of the 128GB available, causes all kinds of issues with the DGX Spark. They need better models and likely need to refine the OS libraries and interfaces to make this a viable system for anything beyond rudimentary R&D for testing inference or model training augmentation (like RAGs or QLoRA training). When I asked the AI coding agent to change the title of the HTML document to use all caps, not only did it take 3-4 minutes to type in the command (very reminiscent of of the days of trying to code on a 2400 baud modem) — it never finished the job. It gave up after a few lines of HTML code.
Summary
In short, the multiagent playbook is not ready for anything other than basic amusement. A “what can this box do” type of test, but only in a very simplistic and rudimentary way. Unlike the single LLM (and more of a Small Language Model) setup, the multiagent setup is mostly non-functional. The UX is poor, and the DGX Spark clearly does not like being taxed at his level. Performance is abysmal and the results are underwhelming. For doing real AI work at this level you’ll clearly need to go to a full on cloud services provider.
Feature Image
AI Generated by Nano Banana
via Galaxy.ai